分析过程基于Linux kernel 3.18.120
内核栈 Linux上进程的相关属性在内核中表示为task_struct,该结构体中stack成员指向进程内核栈的栈底:
1 2 3 4 5 struct task_struct { ... void *stack ; ... }
我们知道Linux的子进程创建都是通过复制父进程的task_struct来进行的,所以可以从系统的0号进程着手分析进程内核栈的大小;0号进程为init_task:
1 struct task_struct init_task = INIT_TASK (init_task );
来看看init_task的stack字段的值:
1 2 3 4 5 6 7 8 9 10 #define INIT_TASK(tsk) \ { \ ... .stack = &init_thread_info, \ ... } ... #define init_thread_info (init_thread_union.thread_info) ... union thread_union init_thread_union;
init_task的stack字段实际上指向thread_union联合体中的thread_info,再来看一下thread_union的结构:
1 2 3 4 union thread_union { struct thread_info thread_info ; unsigned long stack [THREAD_SIZE/sizeof (long )]; };
所以init_task进程的内核栈就是init_thread_union.stack,而thread_info位于内核栈的栈底;内核栈声明为unsigned long类型的数组,其实际大小与平台相关,即为THREAD_SIZE的定义;对于arm32平台,它的定义为:
1 2 3 4 #define THREAD_SIZE_ORDER 1 #define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
而PAGE_SIZE的定义为
1 2 3 4 #define PAGE_SHIFT 12 #define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
所以对于arm32平台,PAGE_SIZE大小为4k,THREAD_SIZE大小为8k;此时可以确定 init_task的内核栈大小为8k
前面提到进程的创建是在内核中拷贝父进程的task_struct,来看一下这部分代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static struct task_struct *dup_task_struct (struct task_struct *orig) struct task_struct *tsk ; struct thread_info *ti ; int node = tsk_fork_get_node(orig); int err; tsk = alloc_task_struct_node(node); ... ti = alloc_thread_info_node(tsk, node); ... err = arch_dup_task_struct(tsk, orig); ... tsk->stack = ti; ... setup_thread_stack(tsk, orig); ... }
在复制task_struct的时候,新的task_struct->stack通过alloc_thread_info_node来分配:
1 2 3 4 5 6 7 8 static struct thread_info *alloc_thread_info_node (struct task_struct *tsk, int node) struct page *page = alloc_kmem_pages_node (node , THREADINFO_GFP , THREAD_SIZE_ORDER ); return page ? page_address(page) : NULL ; }
这里THREAD_SIZE_ORDER为1,所以分配了2个page,所以我们可以确定,进程的内核栈大小为8k。
用户栈大小 用户栈虚拟地址空间最大值 通过ulimit命令可以查看当前系统的进程用户栈的虚拟地址空间上限,单位为kB;
即当前系统中,用户栈的虚拟地址空间上限为8M;为了确认这个值的出处,使用strace,确认ulimit执行过程中,使用了哪些系统调用:
1 2 3 4 -> % strace sh -c "ulimit -s" ... prlimit64(0, RLIMIT_STACK, NULL, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0 ...
接着到内核中查找该系统调用的实现,函数名为SYSCALL_DEFINE4(prlimit64, .......)
1 2 3 4 5 6 7 8 9 10 11 12 13 SYSCALL_DEFINE4(prlimit64, pid_t , pid, unsigned int , resource, const struct rlimit64 __user *, new_rlim, struct rlimit64 __user *, old_rlim) { ... tsk = pid ? find_task_by_vpid(pid) : current; ... ret = do_prlimit(tsk, resource, new_rlim ? &new : NULL , old_rlim ? &old : NULL ); ... }
函数的第一个参数为pid,第二个参数为资源的索引;这里可以理解为查找pid为0的进程中,RLIMIT_STACK的值;函数查找到pid对应的task_struct,然后调用do_prlimit
1 2 3 4 5 6 7 8 9 10 int do_prlimit (struct task_struct *tsk, unsigned int resource, struct rlimit *new_rlim, struct rlimit *old_rlim) struct rlimit *rlim ; ... rlim = tsk->signal->rlim + resource; ... }
do_prlimit的实现为我们指明了到何处去查找RLIMIT_STACK的值,即tsk->signal->rlim + resource;我们知道0号进程为init_task,所以找到init_task->signal->rlim进行确认
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #define INIT_TASK(tsk) \ { ... .signal = &init_signals, \ ... } ... #define INIT_SIGNALS(sig) { \ ... .rlim = INIT_RLIMITS, \ ... }
接着找到INIT_RLIMITS宏的定义
1 2 3 4 5 6 7 8 #define INIT_RLIMITS \ { \ ... [RLIMIT_STACK] = { _STK_LIM, RLIM_INFINITY }, \ ... }
_STK_LIM即为当前系统中,进程用户栈的虚拟地址空间上限:
1 2 3 #define _STK_LIM (8*1024*1024)
当前用户栈虚拟地址空间大小 可以从proc文件系统中,查看进程的虚拟地址空间分布;以init进程为例,其pid为1,可以通过以下命令查看init进程的虚拟地址空间分布,在arm32平台,内核版本3.18.120,init进程的用户栈空间大小为132kB:
1 2 3 4 5 ~ # cat /proc/1/smaps ... beec2000-beee3000 rw-p 00000000 00 :00 0 [stack ] Size: 132 kB ...
仔细观察会发现,任意进程在启动后,其栈空间大小基本都是132kB;在分析原因之前,我们先来看一下进程的虚拟地址空间分布:
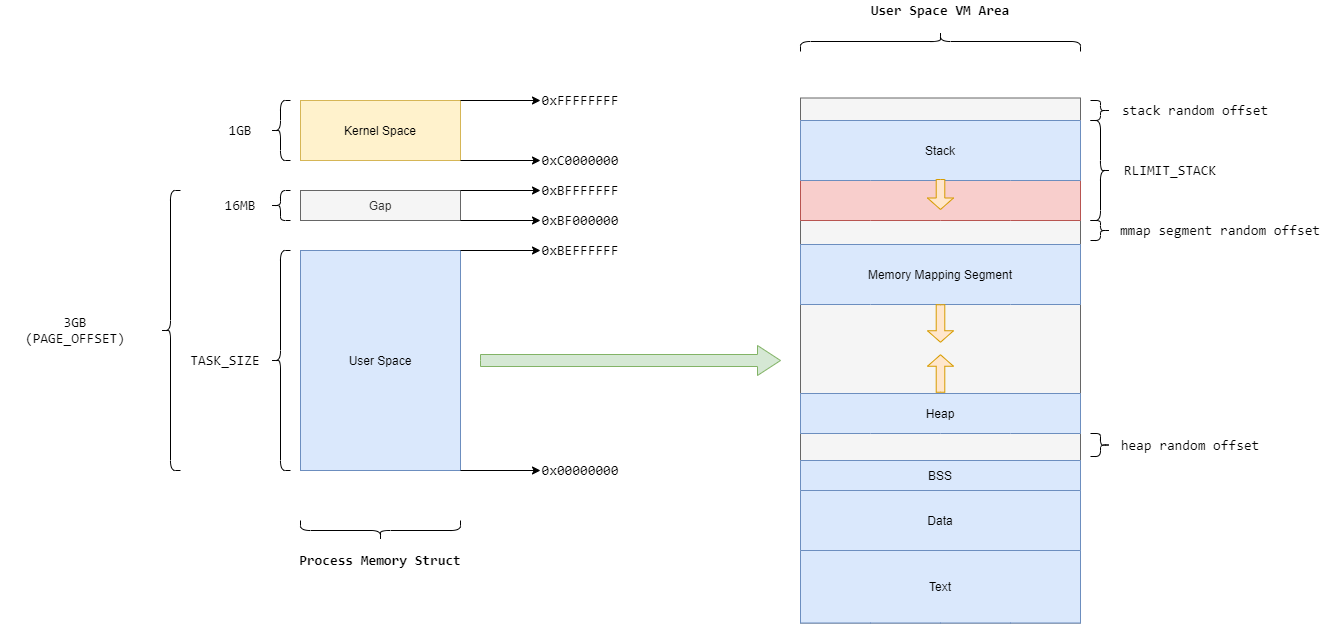
进程的虚拟地址空间大小为4GB,其中内核空间1GB,用户空间3GB,在arm32平台上,二者之间存在一个大小为16M的空隙;用户空间的准确大小为TASK_SIZE:
1 2 3 #define TASK_SIZE (UL(CONFIG_PAGE_OFFSET) - UL(SZ_16M))
即用户空间的地址范围为0x00000000~0xBEFFFFFF。
上图左侧为用户空间内的虚拟空间分布,分别为:用户栈(向下增长),内存映射段(向下增长),堆(向上增长)以及BSS、Data和Text;我们关注的重点在用户空间中的栈空间。
在Linux系统中,运行二进制需要通过exec族系统调用进行,例如execve、execl、execv等,而这些函数最终都会切换到kernel space,调用do_execve_common(),我们从这个函数开始分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static int do_execve_common (struct filename *filename, struct user_arg_ptr argv, struct user_arg_ptr envp) ... file = do_open_exec(filename); ... retval = bprm_mm_init(bprm); ... retval = copy_strings_kernel(1 , &bprm->filename, bprm); ... retval = copy_strings(bprm->envc, envp, bprm); ... retval = copy_strings(bprm->argc, argv, bprm); ... retval = exec_binprm(bprm); ... }
函数中的bprm是类型为struct linux_binprm的结构体,主要用来存储运行可执行文件时所需要的参数,如虚拟内存空间vma、内存描述符mm、还有文件名和环境变量等信息:
1 2 3 4 5 6 7 8 9 10 11 struct linux_binprm { ... struct vm_area_struct *vma ; ... struct mm_struct *mm ; unsigned long p; ... int argc, envc; const char * filename; ... };
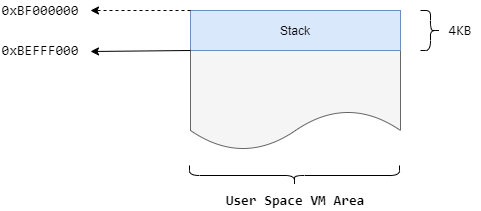
接着回到do_execve_common函数,在调用bprm_mm_init初始化内存空间描述符时,第一次为进程的栈空间分配了一个页:
1 2 3 4 5 6 7 8 9 10 11 12 static int __bprm_mm_init(struct linux_binprm *bprm){ ... vma->vm_end = STACK_TOP_MAX; vma->vm_start = vma->vm_end - PAGE_SIZE; ... }
这里的vma就是进程的栈虚拟地址空间,这段vma区域的结束地址设置为STACK_TOP_MAX,大小为PAGE_SIZE;这两个宏的定义如下:
1 2 3 4 5 6 7 8 9 #define STACK_TOP_MAX TASK_SIZE #define TASK_SIZE (UL(CONFIG_PAGE_OFFSET) - UL(SZ_16M)) #define PAGE_SHIFT 12 #define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
此时,进程的栈空间如下图所示:
继续回到do_execve_common()函数,到目前为止,内核还没有识别到可执行文件的格式,也没有解析可执行文件中各个段的数据;在exec_binprm()中,会遍历在内核中注册支持的可执行文件格式,并调用该格式的load_binary方法来处理对应格式的二进制文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int search_binary_handler (struct linux_binprm *bprm) struct linux_binfmt *fmt ; ... list_for_each_entry(fmt, &formats, lh) { ... retval = fmt->load_binary(bprm); ... } ... }
search_binary_handler()会依次调用系统中注册的可执行文件格式load_binary()方法;load_binary()方法中会自行识别当前二进制格式是否支持;以ELF格式为例,其注册的load_binary方法为load_elf_binary():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static int load_elf_binary (struct linux_binprm *bprm) ... for (i = 0 ; i < loc->elf_ex.e_phnum; i++) { ... retval = kernel_read(bprm->file, elf_ppnt->p_offset, elf_interpreter, elf_ppnt->p_filesz); ... } ... retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP), executable_stack); ... current->mm->start_stack = bprm->p; ... }
该函数的实现比较复杂,这里我们重点关注setup_arg_pages()函数。
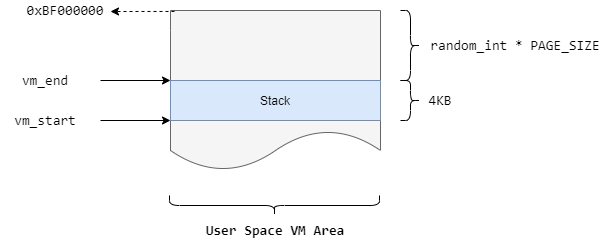
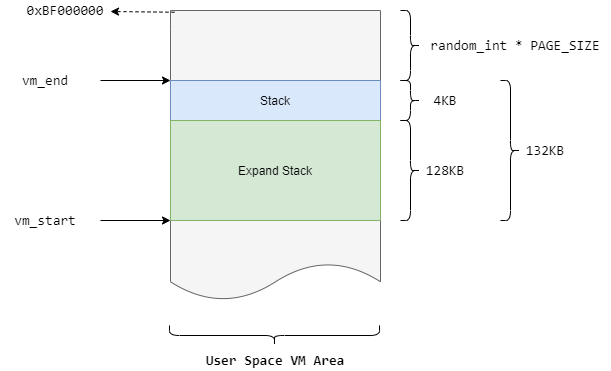
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int setup_arg_pages (struct linux_binprm *bprm, unsigned long stack_top, int executable_stack) ... stack_top = arch_align_stack(stack_top); stack_top = PAGE_ALIGN(stack_top); ... stack_shift = vma->vm_end - stack_top; ... if (stack_shift) { ret = shift_arg_pages(vma, stack_shift); ... } ... stack_expand = 131072U L; ... if (stack_size + stack_expand > rlim_stack) stack_base = vma->vm_end - rlim_stack; else stack_base = vma->vm_start - stack_expand; ... ret = expand_stack(vma, stack_base); ... }
前面我们已经初始化了一个页的栈空间,用来存放二进制文件名、参数和环境变量等;在setup_arg_pages()中,我们把前面这一个页的栈空间移动到stack_top的位置;在调用函数时,stack_top的值是randomize_stack_top(STACK_TOP),即一个随机地址,这里是为了安全性而实现的栈地址随机化;函数通过shift_arg_pages()将页移动到新的地址,移动后的栈如下图所示:
接着回到setup_arg_pages()函数,关注如下代码:
1 2 3 4 5 6 7 8 stack_expand = 131072U L; ... if (stack_size + stack_expand > rlim_stack) stack_base = vma->vm_end - rlim_stack; else stack_base = vma->vm_start - stack_expand; ... ret = expand_stack(vma, stack_base);
expand_stack()函数用来扩展栈虚拟地址空间的大小,stack_base是新的栈基地址,这里的stack_expand是一个固定值,大小为128k,即此处将栈空间扩展128k的大小,扩展后栈空间如下:
所以扩展后的栈虚拟地址空间为4kB+128kB,刚刚好132kB.
栈顶地址随机化 前面介绍setup_arg_pages()函数移动栈顶的时候提到,出于安全原因,会将栈顶移动到一个随机的地址:
1 2 3 4 5 6 7 8 9 10 11 12 static int load_elf_binary (struct linux_binprm *bprm) ... retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP), executable_stack); ... }
这里randomize_stack_top(STACK_TOP)就是将STACK_TOP进行随机化处理,在我们的平台上。STACK_TOP与STACK_TOP_MAX的值相同,为0xBF000000;我们来分析一下randomize_stack_top()函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #ifndef STACK_RND_MASK #define STACK_RND_MASK (0x7ff >> (PAGE_SHIFT - 12)) #endif static unsigned long randomize_stack_top (unsigned long stack_top) unsigned long random_variable = 0 ; if ((current->flags & PF_RANDOMIZE) && !(current->personality & ADDR_NO_RANDOMIZE)) { random_variable = (unsigned long ) get_random_int(); random_variable &= STACK_RND_MASK; random_variable <<= PAGE_SHIFT; } #ifdef CONFIG_STACK_GROWSUP return PAGE_ALIGN(stack_top) + random_variable; #else return PAGE_ALIGN(stack_top) - random_variable; #endif } 函数整体非常好理解,就是获取一个随机值,再根据栈向上还是向下增长,将栈顶地址加上或减去这个随机值;我们重点关注下面两行: ``` C random_variable &= STACK_RND_MASK; random_variable <<= PAGE_SHIFT;
STACK_RND_MASK的值为0x7FF,PAGE_SHIFT为12;第一行将获取的随机值范围限制在0~0x7FF的范围内;第二行将该值左移12位,这样得到的随机数范围就变成了0~0x7FF000,可以理解为栈顶地址是在一个8MB的范围内取一个4kB对齐的随机值 。
线程的用户栈 我们知道在Linux系统上,无论是进程还是线程,都是通过clone系统调用来创建,区别是传入的参数不同;为了确认创建线程时使用的参数,我准备了一个测试程序,然后使用strace来确认:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <stdio.h> #include <stdlib.h> #include <pthread.h> void *function (void *arg) printf ("function call\n" ); } int main () pthread_t thread; pthread_create(&thread, NULL , function, NULL ); pthread_join(thread,NULL ); return 0 ; }
该程序的strace部分输出(在x86平台上运行):
1 clone(child_stack=0x7fd2500d0fb0 , flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tid=[36747 ], tls=0x7fd2500d1700 , child_tidptr=0x7fd2500d19d0 ) = 36747
我们可以看到调用clone的时候传入的flags,其中与内存相关最重要的flags是CLONE_VM;接着我们来看内核部分的源码,仍然从copy_process()函数开始:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 static struct task_struct *copy_process (unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *child_tidptr, struct pid *pid, int trace) ... retval = copy_mm(clone_flags, p); ... } ... static int copy_mm (unsigned long clone_flags, struct task_struct *tsk) struct mm_struct *mm , *oldmm ; ... oldmm = current->mm; ... if (clone_flags & CLONE_VM) { atomic_inc(&oldmm->mm_users); mm = oldmm; goto good_mm; } ... }
在copy_mm中,检查了clone_flags,如果设置了CLONE_VM,那么将当前task_struct->mm指针赋值给新的task_struct->mm;所以我们可以得到结论,通过pthread库创建的线程,其内存是与主线程共享的。